
In August and September there will be a series of events covering the zEnterprise technology. The events are complimentary.
In the 1/2 day event you can get an overview of the new system, with all its hardware and software innovations. And you can find out how zEnterprise incorporates advanced industry and workload strategies to reduce your total cost of ownership/acquisition. You will be also able to put questions to IBM and industry experts from many areas, including zEnterprise, Business Intelligence and Tivoli.
Here is a list of cities and dates:
Minneapolis, MN August 17
Houston, TX August 19
Detroit, MI September 14
Montreal, QC September 14
Ottawa, ON September 15
Columbus, OH September 16
Hartford, CT September 16
Toronto, ON September 21
Jacksonville, FL September 21
Atlanta, GA September 22
Los Angeles, CA September 22
Here is a link to register (the price is right, the event is free):
https://www-950.ibm.com/events/wwe/grp/grp017.nsf/v16_events?openform&lp=systemzbriefings&locale=en_US
Friday, July 30, 2010
Wednesday, July 28, 2010
More efficient reporting in OMEGAMON DB2 PM/PE
This was an interesting issue that I helped a customer with recently in the area of OMEGAMON DB2 reporting.
The customer wanted to create a DB2 Accounting summary report, but just for a select plan, in this case DSNTEP2. Out of several million accounting records in SMF, there were, on a typical day, a few hundred relevant accounting records. When the customer ran the report, the batch job would run for almost 2 hours, and use a fair amount of CPU considering the amount of report data being generated. Even though the job was reading through several million accounting records to create the report, this seemed like an excessively long run time.
I reviewed the OMEGAMON DB2 reporter documentation (SC19-2510), and noted an entry that referred to the fact using the GLOBAL option would help reporter performance. The doc says: "Specify the filters in GLOBAL whenever you can, because only the data that passes through the GLOBAL filters is processed further. The less data OMEGAMON XE for DB2 PE needs to process, the better the performance."
So for example if all you want is a specific plan/authid try the following:
GLOBAL
INCLUDE (AUTHID (USERID01))
INCLUDE (PLANNAME (DSNTEP2)) .....
The net result for this user was that the run time for the same report dropped to just a few minutes, and CPU usage of the batch job dropped dramatically, as well. Take advantage of this option, when you can.
The customer wanted to create a DB2 Accounting summary report, but just for a select plan, in this case DSNTEP2. Out of several million accounting records in SMF, there were, on a typical day, a few hundred relevant accounting records. When the customer ran the report, the batch job would run for almost 2 hours, and use a fair amount of CPU considering the amount of report data being generated. Even though the job was reading through several million accounting records to create the report, this seemed like an excessively long run time.
I reviewed the OMEGAMON DB2 reporter documentation (SC19-2510), and noted an entry that referred to the fact using the GLOBAL option would help reporter performance. The doc says: "Specify the filters in GLOBAL whenever you can, because only the data that passes through the GLOBAL filters is processed further. The less data OMEGAMON XE for DB2 PE needs to process, the better the performance."
So for example if all you want is a specific plan/authid try the following:
GLOBAL
INCLUDE (AUTHID (USERID01))
INCLUDE (PLANNAME (DSNTEP2)) .....
The net result for this user was that the run time for the same report dropped to just a few minutes, and CPU usage of the batch job dropped dramatically, as well. Take advantage of this option, when you can.
zEnterprise and Tivoli
The new zEnterprise systems are bigger, faster, better. More power and superior integration are important benefits of the technology.
So the question may be, where do IBM Tivoli solutions fit into this new computing capability? The short answer is that the Tivoli approach fits very well within this paradigm. One of the strengths of the Tivoli approach is integration and flexibility. The exsiting Tivoli suite of solutions (for example your OMEGAMON monitoring technology) will continue to run and provide value in this environment.
As details emerge, I will do more posts on how Tivoli will continue to exploit the new zEnterprise technology. Stay tuned.
So the question may be, where do IBM Tivoli solutions fit into this new computing capability? The short answer is that the Tivoli approach fits very well within this paradigm. One of the strengths of the Tivoli approach is integration and flexibility. The exsiting Tivoli suite of solutions (for example your OMEGAMON monitoring technology) will continue to run and provide value in this environment.
As details emerge, I will do more posts on how Tivoli will continue to exploit the new zEnterprise technology. Stay tuned.
Friday, July 23, 2010
About the new zEnterprise system
Yesterday was the announcement of the new zEnterprise system. Bigger, faster, better. That seems to be the bottom line.
Here are some of the specs from the IBM announcement page:
"At its core is the first model of the next generation System z, the zEnterprise 196 (z196). The industry’s fastest and most scalable enterprise system has 96 total cores running at an astonishing 5.2 GHz, and delivers up to 60% improvement in performance per core and up to 60% increase in total capacity."
Here is a link to the announcement:
http://www-03.ibm.com/systems/z/news/announcement/20100722_annc.html
Here are some of the specs from the IBM announcement page:
"At its core is the first model of the next generation System z, the zEnterprise 196 (z196). The industry’s fastest and most scalable enterprise system has 96 total cores running at an astonishing 5.2 GHz, and delivers up to 60% improvement in performance per core and up to 60% increase in total capacity."
Here is a link to the announcement:
http://www-03.ibm.com/systems/z/news/announcement/20100722_annc.html
Wednesday, July 21, 2010
Reminder - Upcoming webcasts tomorrow
Tomorrow, July 22nd, there will be two webcasts that you may find interesting.
The first is my webcast, "Top 10 Problem Solving Scenarios using IBM OMEGAMON and the Tivoli Enterprise Portal". This event is at 11 AM Eastern time. Here's a link to register and attend:
http://www.ibm.com/software/systemz/telecon/22jul
The second event is a major new technology announcement for System z. That event happens from 12 PM to 2 PM Eastern time. Here is a link for this event:
http://events.unisfair.com/rt/ibm~wos?code=614comm
The first is my webcast, "Top 10 Problem Solving Scenarios using IBM OMEGAMON and the Tivoli Enterprise Portal". This event is at 11 AM Eastern time. Here's a link to register and attend:
http://www.ibm.com/software/systemz/telecon/22jul
The second event is a major new technology announcement for System z. That event happens from 12 PM to 2 PM Eastern time. Here is a link for this event:
http://events.unisfair.com/rt/ibm~wos?code=614comm
Take advantage of RSS feeds to stay up to data

I was working with a customer recently, and we were talking about ways to stay current on what is happening in terms of issues and available fixes for their IBM Tivoli products.
IBM Tivoli support provides RSS feeds on all its relevant support pages. RSS feeds are a great way to keep track of what is happening, and it's easy to set up and use. All you need is a link to where the RSS feeds are, and a RSS reader (I use Google reader, it's free).
Here is a screen shot of one of the main RSS feeds pages. It has links for all the relevant IBM Tivoli products. Here is the URL for the page:
Thursday, July 15, 2010
Analyzing the CPU usage of OMEGAMON
OK. As I suggested last week, you look at your SMF data, or something comparable for a typical 24 hour period, and now you have an idea of which OMEGAMON address spaces use how much CPU. In general, you will find that some tasks will use more CPU resource than others. What's normal? As the saying goes, it depends. The next step is to get of list of how much the tasks use, and look for some patterns.
For example:
High CPU usage in the CUA and Classic task for a given OMEGAMON. Maybe an autorefresh user in CUA that is driving the Classic as well. Could also be OMEGAVIEW sampling at too frequent a rate, thereby driving the other tasks (check your OMEGAVIEW session definition).
CUA is low, but Classic interface is high. Now you can ignore autorefresh in CUA or OMEGAVIEW session definition. But, you still could have a user in Classic doing autorefresh (remember .VTM to check). This could be automation logging on to Classic to check for excpetions. This could also be history collection. Near term history in OMEGAMON DB2 and IMS have costs. Epilog in IMS has cost. Also, CICS task history (ONDV) can store a lot of information in a busy environment.
Classic and CUA are low, but TEMA (agent) tasks are high: Start looking at things like situations distributed to the various TEMAs. Look at the number of situations, the situation intervals, and are there a lot of situations with Take Actions.
TEMS is high: This could be many things. DASD collection. Enqueue collection. WLM collection. Sysplex proxy (if defined on this TEMS). Situation processing for the z/OS TEMA (which runs inside the TEMS on z/OS). Policy processing (if policies being used). Just to name a few things to check.
The above is not an exhaustive list, but it is a starting point in the analysis process. The best strategy is to determine certain tasks to focus on, and then begin your analysis there.
For example:
High CPU usage in the CUA and Classic task for a given OMEGAMON. Maybe an autorefresh user in CUA that is driving the Classic as well. Could also be OMEGAVIEW sampling at too frequent a rate, thereby driving the other tasks (check your OMEGAVIEW session definition).
CUA is low, but Classic interface is high. Now you can ignore autorefresh in CUA or OMEGAVIEW session definition. But, you still could have a user in Classic doing autorefresh (remember .VTM to check). This could be automation logging on to Classic to check for excpetions. This could also be history collection. Near term history in OMEGAMON DB2 and IMS have costs. Epilog in IMS has cost. Also, CICS task history (ONDV) can store a lot of information in a busy environment.
Classic and CUA are low, but TEMA (agent) tasks are high: Start looking at things like situations distributed to the various TEMAs. Look at the number of situations, the situation intervals, and are there a lot of situations with Take Actions.
TEMS is high: This could be many things. DASD collection. Enqueue collection. WLM collection. Sysplex proxy (if defined on this TEMS). Situation processing for the z/OS TEMA (which runs inside the TEMS on z/OS). Policy processing (if policies being used). Just to name a few things to check.
The above is not an exhaustive list, but it is a starting point in the analysis process. The best strategy is to determine certain tasks to focus on, and then begin your analysis there.
Wednesday, July 14, 2010
More on Autorefresh
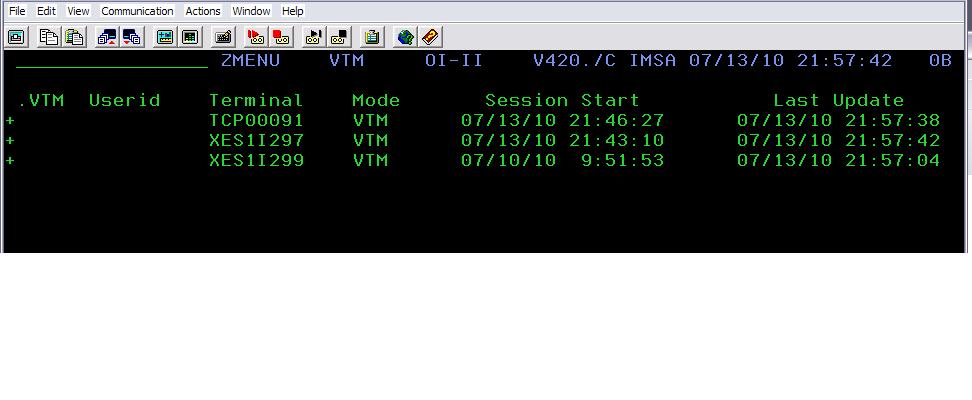
I posted earlier on the costs of Autorefresh when over-using it in the Classic interface. Which then brings us to the question: how do you determine if someone is using Autorefresh, and what are they likely using as a refresh interval?
There is one very handy classic command that can tell you a lot about what is going on. The .VTM command will show information on sessions connected to the Classic task. Most important, it will show the last time the session was updated, either by the user hitting enter, or the screen being refreshed via Autorefresh.
Here is an example of the .VTM command in use. In the example you see three sessions. The middle session is my own session, and I can infer this because the Last Update time stamp matches the time on the top line of the screen. The bottom line is probably a session between OMEGAVIEW and OMEGAMON. The top line is the one of interest. If I refresh my screen a few times, I will see that the Last Update column for the session in question increments on a fairly regular basis. By watching that number you can infer that the top line is a session in Autorefresh mode, and what the interval is (in this example it is at the Classic default of 5 seconds).
Once you know that Autorefresh is being used, the next step is to locate the user in question, and ask them to either set the interval to a higher number, or to discontinue using Autorefresh mode.
Wednesday, July 7, 2010
Understanding the CPU usage of OMEGAMON
OMEGAMON installs as a set of started tasks on z/OS. Which started tasks get installed depends, of course, upon which OMEGAMONs from the suite you are running, and what features of OMEGAMON you may have configured. For example, if you are running OMEGAMON XE for DB2 or OMEGAMON XE for CICS, the agent task for the XE GUI interface (aka the TEMA), is something that you may or may not run, depending upon whether or not you use the Tivoli Portal GUI interface. The TEMA is not required if all you are doing is classic 3270 interface.
When you are looking at optimizing OMEGAMON, the first thing to understand is the CPU usage of each of the OMEGAMON address spaces. I suggest doing something like looking at SMF30 record output (or an equivalent), for each of the OMEGAMON started tasks, and generate a report that will let you see a summary of CPU usage by task. Look at the data for a selected 24 hour period, and look for patterns in the data. For example, first look for which tasks use the highest CPU of the various OMEGAMON tasks. Different installations may have different tasks that use more CPU, when compared to the other tasks. It really will depend upon what OMEGAMONs you have installed, and what you have configured. Once you have identified which OMEGAMON started tasks are using the most cycles relative to the other OMEGAMON tasks, that will provide a starting point for where to begin your analysis.
When you are looking at optimizing OMEGAMON, the first thing to understand is the CPU usage of each of the OMEGAMON address spaces. I suggest doing something like looking at SMF30 record output (or an equivalent), for each of the OMEGAMON started tasks, and generate a report that will let you see a summary of CPU usage by task. Look at the data for a selected 24 hour period, and look for patterns in the data. For example, first look for which tasks use the highest CPU of the various OMEGAMON tasks. Different installations may have different tasks that use more CPU, when compared to the other tasks. It really will depend upon what OMEGAMONs you have installed, and what you have configured. Once you have identified which OMEGAMON started tasks are using the most cycles relative to the other OMEGAMON tasks, that will provide a starting point for where to begin your analysis.
Wednesday, June 30, 2010
Looking at Autorefresh
We've discussed at length DASD monitoring considerations, and the cost of monitoring when it comes to DASD performance metric collection. What I would like to do next is take a look at other aspects of the cost of monitoring, and take into account such things as optimization of CPU required for monitoring.
One of the first things to look at when it comes to looking at the cost of monitoring is if you and your users are employing Autorefresh. Autorefresh implies that OMEGAMON will be regenerating a given monitoring display (screenspace, CUA screen, or TEP workspace) on a timed interval. In Classic and CUA interface, Autorefresh is set in the session options, and if used extensively, Autorefresh can measurably drive up the the CPU usage of the Classic and CUA tasks. For example, if you have multiple users, each running a display on a relatively tight (10 seconds or less) interval, OMEGAMON is doing a lot of work just painting and re-painting screens on a continuous basis.
The recommendations are as follows:
Limit the use of Autorefresh
If you must use Autorefresh, set it on a higher interval (60 seconds or higher)
Better yet, if you must use Autorefresh, us the Tivoli Portal to drive the display. The TEP has more options to control Autorefresh, and you will be moving some of the cost of screen rendering from the collection tasks to the TEP infrastructure.
One of the first things to look at when it comes to looking at the cost of monitoring is if you and your users are employing Autorefresh. Autorefresh implies that OMEGAMON will be regenerating a given monitoring display (screenspace, CUA screen, or TEP workspace) on a timed interval. In Classic and CUA interface, Autorefresh is set in the session options, and if used extensively, Autorefresh can measurably drive up the the CPU usage of the Classic and CUA tasks. For example, if you have multiple users, each running a display on a relatively tight (10 seconds or less) interval, OMEGAMON is doing a lot of work just painting and re-painting screens on a continuous basis.
The recommendations are as follows:
Limit the use of Autorefresh
If you must use Autorefresh, set it on a higher interval (60 seconds or higher)
Better yet, if you must use Autorefresh, us the Tivoli Portal to drive the display. The TEP has more options to control Autorefresh, and you will be moving some of the cost of screen rendering from the collection tasks to the TEP infrastructure.
Thursday, June 24, 2010
Webcast on System Automation V3.3
Sorry for the short notice, but there will be an interesting webcast on June 24th on "Achieving high availability and resiliency for your business with the new capabilities of Tivoli System Automation Version 3.3". If you can't make the event, you can always download and listen to the material later.
Here's the URL to register and attend:
http://www-01.ibm.com/software/os/systemz/telecon/24jun/index.html?S_TACT=100GV27M&S_CMP=5x5
Broadcast date/time: June 24, 2010, 11 a.m., EDT
The new Version 3.3 of Tivoli System Automation extends it's industry-leading capabilities through increased integration with Tivoli business management and monitoring solutions, additional automation controls, and simplification of automation activities.
In this session, the discussion will include how IBM Tivoli System Automation solutions can:
Provide remote management
Alerting and escalation as an adjunct to automation and high-availability solutions
Leverage automation technology for service management and business continuity
Speaker: Allison Ferguson, Automation Solutions Product Manager
Here's the URL to register and attend:
http://www-01.ibm.com/software/os/systemz/telecon/24jun/index.html?S_TACT=100GV27M&S_CMP=5x5
Broadcast date/time: June 24, 2010, 11 a.m., EDT
The new Version 3.3 of Tivoli System Automation extends it's industry-leading capabilities through increased integration with Tivoli business management and monitoring solutions, additional automation controls, and simplification of automation activities.
In this session, the discussion will include how IBM Tivoli System Automation solutions can:
Provide remote management
Alerting and escalation as an adjunct to automation and high-availability solutions
Leverage automation technology for service management and business continuity
Speaker: Allison Ferguson, Automation Solutions Product Manager
Many thanks and keep stopping by....
Since January we've had over 1000 first time visitors to this blog. The traffic has been very good, and I appreciate all the interest.
I will continue to post technical content, and upcoming events. I have quite a bit more to cover just in the area of OMEGAMON optimization.
In the future I will be doing more to make this blog more interactive. Feel free to post comments. Also, if you have a topic of interest, please let me know. You can put it in a comment on this blog, or you can email me at woodse@us.ibm.com.
thanks again
I will continue to post technical content, and upcoming events. I have quite a bit more to cover just in the area of OMEGAMON optimization.
In the future I will be doing more to make this blog more interactive. Feel free to post comments. Also, if you have a topic of interest, please let me know. You can put it in a comment on this blog, or you can email me at woodse@us.ibm.com.
thanks again
Wednesday, June 23, 2010
Upcoming IBM webcast and virtual event
On July 22nd from 12 to 2 PM ET, IBM will be holding a virtual event on powerful new technology. Today's IT environments are built using diverse computing technologies x86, Unix, Linux, and z/OS. On July 22nd IBM will be unveiling a solution designed to integrate enterprise systems, people and processes - so they work together as one.
In the virtual event you will have the opportunity to:
- Be among the first to receive the latest technology breakthrough updates
- Network with your peers and IBM subject matter experts
- Participate in online discussions
- Download the latest whitepapers and brochures
- Meet the experts
- Live discussion with Q&A
To attend the virtual event go to the following URL:
http://events.unisfair.com/rt/ibm~wos?code=614comm
In the virtual event you will have the opportunity to:
- Be among the first to receive the latest technology breakthrough updates
- Network with your peers and IBM subject matter experts
- Participate in online discussions
- Download the latest whitepapers and brochures
- Meet the experts
- Live discussion with Q&A
To attend the virtual event go to the following URL:
http://events.unisfair.com/rt/ibm~wos?code=614comm
Friday, June 18, 2010
OMEGAMON Storage ICAT configuration considerations

When you are installing and configuring OMEGAMON XE For Storage there are quite a few options in the ICAT installation panels. Most of these options are fairly straight forward (such as sampling intervals for tape, cache control units, etc.). But, as I've mentioned in earlier posts, the most critical options revolve around the specification of the DASD collection options.
There are several options that control DASD collection, and there are some subtleties to the optimal way to specify collection. In the example shown here, Option 2 is where you can specify DASD collection frequency, and Option 3 is where you can specify devices to exclude from monitoring. If you can exclude some devices from ongoing monitoring, it may be a good idea to do so, and save the cost of monitoring.
Option 2 (DASD Device Monitoring) is the most critical panel to review. When you set up collection options here, you can either collect information every nth I/O (sample count) or collect when the device exceeds a specified MSR (millisecond response time) threshold. The example screen shot I show, has the default configuration panel. What you get by default is every I/O will be monitored, so my first recommendation is to not just automatically take the default. Take the time to configure the options on this panel.
First you can create an entry that will specify a VOLSER or device range. Once you have specified your devices, you then have a choice of monitoring I/O based on sampling (every n I/Os) or monitoring the device if a specified MSR threshold is exceeded. In the Monitor Status field, if you specify ON, then you will monitior based on the number specified in the Sample cnt/MSR field. But, if you enter MSR in the Monitoring Status option, I/O monitoring will happen if the device exceeds the MSR threshold. The Sample cnt/MSR field is treated as an MSR level setting, and the other part of the magic is that the MSR/exception trip count specified in the top portion of the panel comes into play.
Perhaps a little confusing, but obviously these options make a big difference in terms of how much data is gathered on an ongoing basis. If you want to keep the cost of collection down, then consider using the MSR option to collect when exceptions occur. If you want more data on an ongoing basis, then consider the sample approach, but set the sample frequency higher than the defualt of 1 (which means collect everything).
Wednesday, June 16, 2010
Upcoming Tivoli Enterprise Portal webcast
I will be doing a webcast next month on "Top 10 Problem Solving Scenarios using IBM OMEGAMON and the Tivoli Enterprise Portal". The presentation will look at what I consider to be one of the strengths of the Tivoli Portal, its power as a problem isolation and analysis tool. We will look at examples from all the core OMEGAMONs.
The webcast is July 22nd at 10 AM Eastern time. It's a free webcast, so the price is right. Here's a link to register and attend:
http://www.ibm.com/software/systemz/telecon/22jul
The webcast is July 22nd at 10 AM Eastern time. It's a free webcast, so the price is right. Here's a link to register and attend:
http://www.ibm.com/software/systemz/telecon/22jul
Monday, June 14, 2010
New OMEGAMON configuration methods
For years OMEGAMON users have installed and configured the product using an ISPF based dialog called ICAT. ICAT has been the primary mechanism to configure and manage all the core OMEGAMON tools (OMEGAMON for z/OS, CICS, DB2, IMS, Storage, Networks).
Over the past few months a new configuration method, called Parmlib, has been rolling out. Phase 2 of Parmlib support became available in May. Parmlib is intended to be an easier to use alternative to the ICAT process. In the June issue of IBM System z Advisor, Jeff Lowe has written an article that talks about Parmlib. If you are responsible for installation and configuration of OMEGAMON, you will find this article of interest.
Here is a link to the article:
http://www-01.ibm.com/software/tivoli/systemz-advisor/2010-06/config-for-omegamon.html
Over the past few months a new configuration method, called Parmlib, has been rolling out. Phase 2 of Parmlib support became available in May. Parmlib is intended to be an easier to use alternative to the ICAT process. In the June issue of IBM System z Advisor, Jeff Lowe has written an article that talks about Parmlib. If you are responsible for installation and configuration of OMEGAMON, you will find this article of interest.
Here is a link to the article:
http://www-01.ibm.com/software/tivoli/systemz-advisor/2010-06/config-for-omegamon.html
Friday, June 11, 2010
OMEGAMON Storage - Application level monitoring

OMEGAMON XE for Storage offers the flexibility to monitor DASD and I/O at the level of the application. What this means is that you can use the tool to focus your I/O monitoring strategy on the most critical applications, without having the need to monitor the entire DASD complex.
The example shown here shows how you can enable Application level monitoring. To enable application monitoring you need to create a situation to invoke collection. The primary parts of the situation are the application name (which can be wildcarded to include multiple tasks), the monitor switch (Y/N), and monitor I/O option (which controls if you want data set level monitoring). Given these options you have the flexibility to control what tasks you want to gather I/O information about, and whether you need data set level I/O detail.
The picture here shows an example of how to specify the situation to control application level monitoring.
Thursday, June 10, 2010
OMEGAMON Storage - User DASD Groups
OMEGAMON XE For Storage has many collection options for gathering DASD performance and space management information. User DASD groups are one option I find most interesting in that it gives the user considerable flexibility in terms of how DASD data is gathered and displayed. This flexibility is useful in terms of being able to control the cost of DASD monitoring.
A user DASD group is a user-defined logical grouping of DASD volumes related according to specific criteria. You can define a user DASD group based on volume name, device address, SMS storage group, or one or more aspects of the DASD device (examples include fragmentation index and MSR time). Once the user DASD group is defined, you can use the User DASD Group Performance and User DASD Group Space workspaces to view aggregated performance and space metrics for the group.
User DASD groups can be defined in a couple ways. One is via member hilev.RKANPARU(KDFDUDGI). The KDFDUDGI member allows for the definition of a group based on volume, a range of devices, or SMS storage group name.
Another way to create a user DASD group is via the Tivoli Portal (assuming V4.20 Interim Feature 2 is installed). In the TEP select the User DASD Groups Performance node on the navigation tree, right-click any row on the table view, and select Add Group from the menu. As before, the user may specify constraints by volume, device address, device range, SMS storage group, or volume attribute. There is also an attributes tab to specify the attribute constraints that are used in conjunction with the DASD device constraints specified. There is a drop-down list in the attribute column to specify the attribute information to be used.
I like user DASD groups because it provides a way to control monitoring options for various types of devices. Device architecture and usage varies in many enterprises. Being able to group devices makes the analysis more meaningful for a given environment.
A user DASD group is a user-defined logical grouping of DASD volumes related according to specific criteria. You can define a user DASD group based on volume name, device address, SMS storage group, or one or more aspects of the DASD device (examples include fragmentation index and MSR time). Once the user DASD group is defined, you can use the User DASD Group Performance and User DASD Group Space workspaces to view aggregated performance and space metrics for the group.
User DASD groups can be defined in a couple ways. One is via member hilev.RKANPARU(KDFDUDGI). The KDFDUDGI member allows for the definition of a group based on volume, a range of devices, or SMS storage group name.
Another way to create a user DASD group is via the Tivoli Portal (assuming V4.20 Interim Feature 2 is installed). In the TEP select the User DASD Groups Performance node on the navigation tree, right-click any row on the table view, and select Add Group from the menu. As before, the user may specify constraints by volume, device address, device range, SMS storage group, or volume attribute. There is also an attributes tab to specify the attribute constraints that are used in conjunction with the DASD device constraints specified. There is a drop-down list in the attribute column to specify the attribute information to be used.
I like user DASD groups because it provides a way to control monitoring options for various types of devices. Device architecture and usage varies in many enterprises. Being able to group devices makes the analysis more meaningful for a given environment.
Friday, June 4, 2010
Access System z from a Smart Phone
If your business is looking at exploiting technologies like the iPhone or the Droid, fear not, z/OS can work in this environment. Here is a link to an interesting IBM Red Book that goes into how it's possible to combine the traditional strengths of the mainframe to manage large volumes of data and run business transactions with the Web 2.0 paradigm. And to take advantage of simpler interfaces, better integration among different services, lightweight protocols for communication, and much more, together with the availability, security, and reliability of mainframe data.
Here is the link to the Red Book:
http://www.redbooks.ibm.com/Redbooks.nsf/RedbookAbstracts/sg247836.html?Open
Here is the link to the Red Book:
http://www.redbooks.ibm.com/Redbooks.nsf/RedbookAbstracts/sg247836.html?Open
Thursday, June 3, 2010
More on DASD monitoring - OMEGAMON XE For Storage
We've discussed DASD monitoring and the cost of monitoring for several of the OMEGAMON solutions. Now lets consider OMEGAMON XE For Storage, and the cost of monitoring considerations for this solution. As the name implies, OMEGAMON XE For Storage is an OMEGAMON solution focused on the monitoring of DASD on the z/OS platform. But, OMEGAMON Storage provides more than just DASD monitoring. OMEGAMON Storage also provides information on virtual tape, channels, control units, cache controllers, HSM activity, shared DASD, and even more. Another thing to be aware of is that OMEGAMON Storage has been evolving over the years, and has morphed into a much broader storage management, as well as a monitoring tool. OMEGAMON Storage now includes integration with a array of Tivoli Storage solutions, including HSM and backup tools, via the Tivoli Enterprise Portal.
Referring back to a primary consideration I mentioned in earlier posts, the more data you ask for, the more potential cost from a cost of monitoring perspective. OMEGAMON Storage certainly falls into this area. OMEGAMON Storage provides the ability to monitor storage at many different levels: shared DASD, the individual LPAR, the channel level, the controller level, the UCB level, even down to the individual dataset level. The user also has the ability to monitor DASD, I/O, and space utilization from the perspective of the workload applications on z/OS, and also to make user defined groups for monitoring and space analysis.
Clearly, OMEGAMON Storage provides useful and detailed information. It is important that the user have a well conceived plan when deploying OMEGAMON Storage to avoid redundant monitoring cost. When installing OMEGAMON Storage, the tool is usually installed on each LPAR in the z/OS environment. In a shared DASD environment, probably the first recommendation is to have the OMEGAMON Storage instance on a specified LPAR in the shared environment be the primary collection point for DASD information, thus avoiding redundant collection of DASD information on multiple LPARs.
There are quite a few more considerations for the set up and optimization of OMEGAMON Storage, and I will get into these in more detail in later posts.
Referring back to a primary consideration I mentioned in earlier posts, the more data you ask for, the more potential cost from a cost of monitoring perspective. OMEGAMON Storage certainly falls into this area. OMEGAMON Storage provides the ability to monitor storage at many different levels: shared DASD, the individual LPAR, the channel level, the controller level, the UCB level, even down to the individual dataset level. The user also has the ability to monitor DASD, I/O, and space utilization from the perspective of the workload applications on z/OS, and also to make user defined groups for monitoring and space analysis.
Clearly, OMEGAMON Storage provides useful and detailed information. It is important that the user have a well conceived plan when deploying OMEGAMON Storage to avoid redundant monitoring cost. When installing OMEGAMON Storage, the tool is usually installed on each LPAR in the z/OS environment. In a shared DASD environment, probably the first recommendation is to have the OMEGAMON Storage instance on a specified LPAR in the shared environment be the primary collection point for DASD information, thus avoiding redundant collection of DASD information on multiple LPARs.
There are quite a few more considerations for the set up and optimization of OMEGAMON Storage, and I will get into these in more detail in later posts.
Subscribe to:
Posts (Atom)

